VAFlow:
Video-to-Audio Generation with Cross-Modality Flow Matching
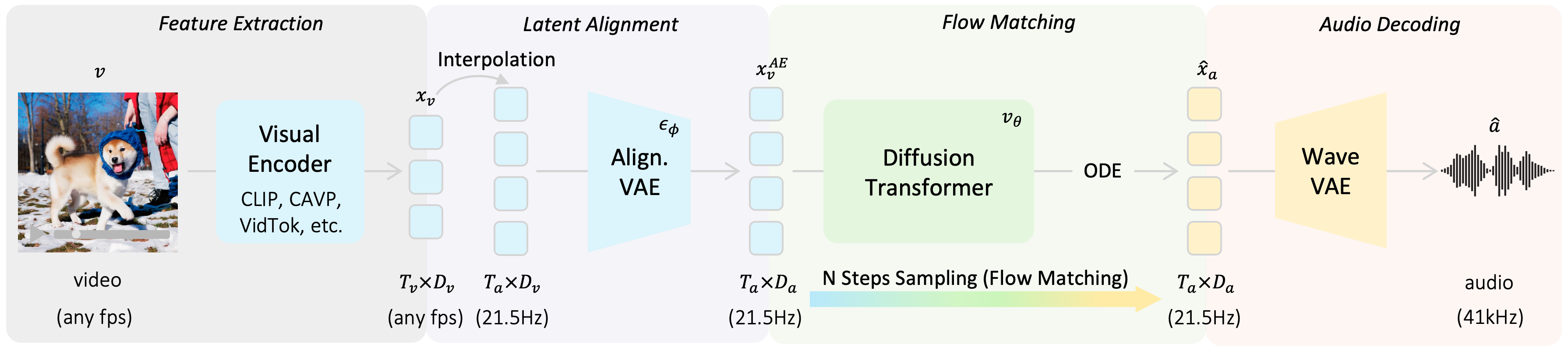
Video-to-audio (V2A) generation aims to synthesize temporally aligned, realistic sounds for silent videos, a critical capability for immersive multimedia applications. Current V2A methods, predominantly based on diffusion or flow models, rely on suboptimal noise-to-audio paradigms that entangle cross-modal mappings with stochastic priors, resulting in inefficient training and convoluted transport paths. We propose VAFlow, a novel flow-based framework that directly models the video-to-audio distributional transformation, eliminating dependency on noise priors. To address modality discrepancies, we employ an alignment variational autoencoder (VAE) that compresses heterogeneous video features into audio-aligned latent spaces while preserving spatiotemporal semantics. By retaining cross-attention mechanisms between video features and flow blocks, our architecture enables classifier-free guidance within video source-driven generation. Without external data or complex training tricks, VAFlow achieves state-of-the-art performance on VGGSound benchmark, surpassing even text-augmented models in audio fidelity (Fréchet Distance, FD), diversity (Inception Score: IS), and alignment (KL). Our work establishes a new paradigm for V2A generation through a direct, simple but effect video-to-audio distribution transformation with flow matching.